COURSE CONTENT:
- Week 1 - Interrupted Time Series
- Week 2 - Difference-in-Difference Models
- Week 3 - Panel Data with Fixed Effects
- Week 4 - Instrumental Variables
- Week 5 - Regression Discontinuity Design
- Week 6 - Logistic Regression
- Week 7 - Propensity Score Matching
Week 1 - Interrupted Time Series
Due Saturday, August 29th
Resources:
Bernal, J. L., Cummins, S., & Gasparrini, A. (2017). Interrupted time series regression for the evaluation of public health interventions: a tutorial. International journal of epidemiology, 46(1), 348-355. [PDF]
Chapter on Interrrupted Time Series [PDF]: From Shadish, W. R., Cook, T. D., & Campbell, D. T. (2002). Experimental and quasi-experimental designs for generalized causal inference. Boston: Houghton Mifflin.
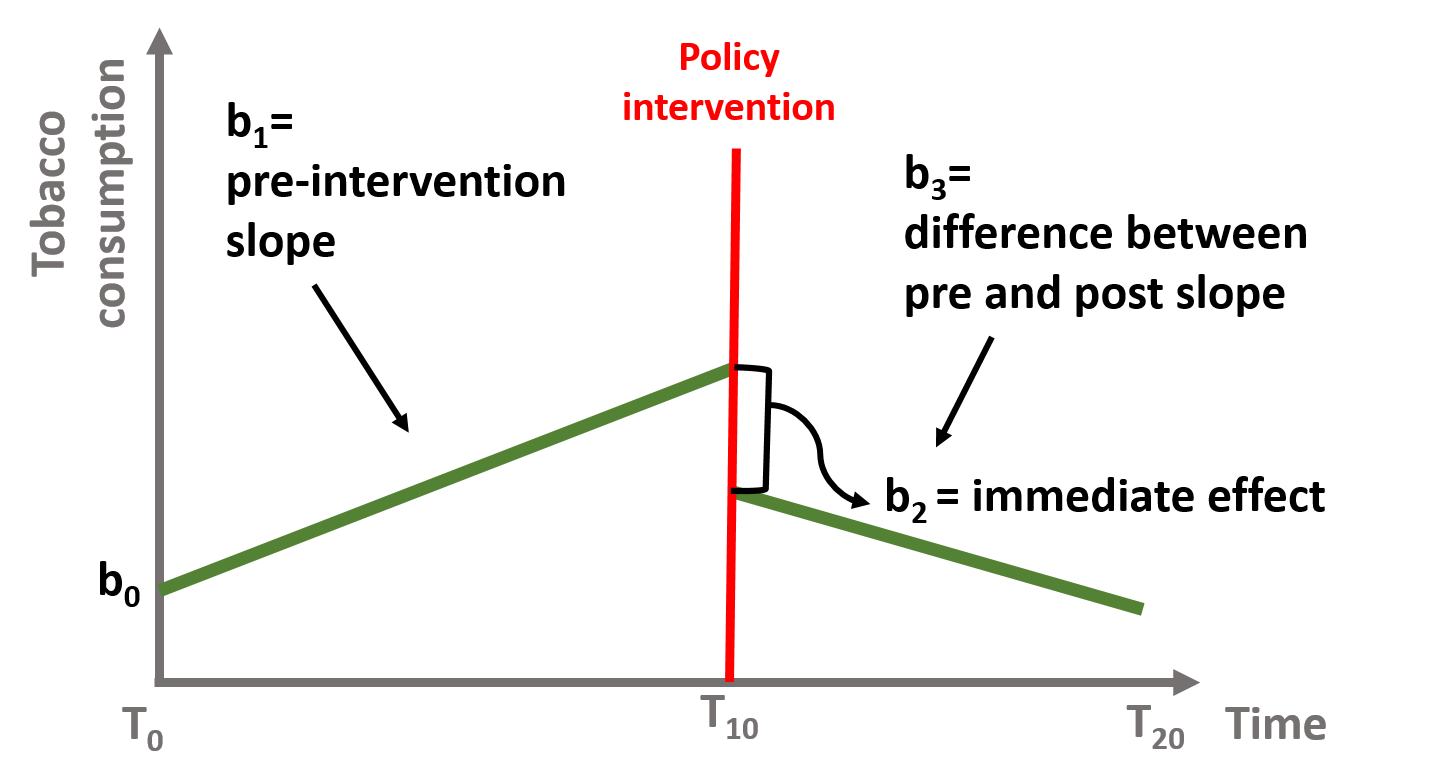
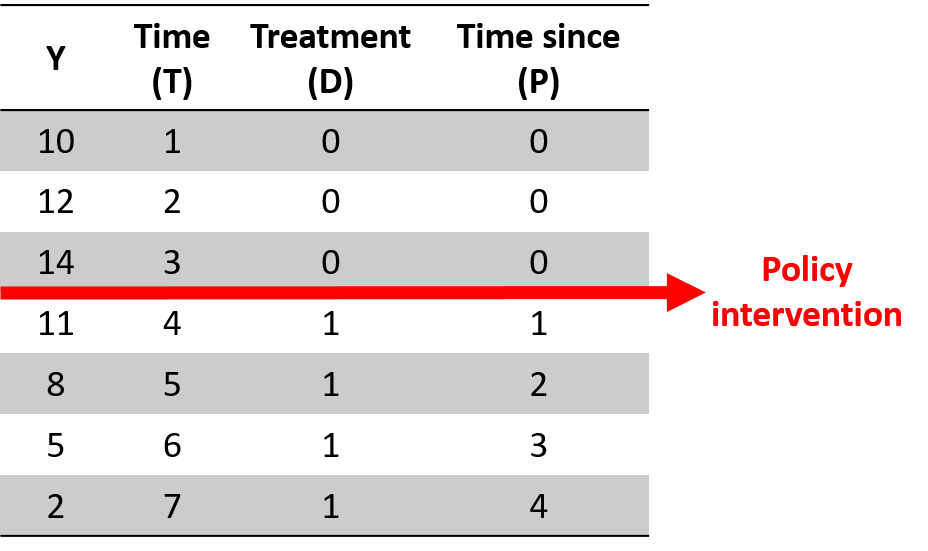
Y = b0 + (b1)(T) + (b2)(D) + (b3)(P) + e
# Interrupted Time Series Model
# b1 = pre-intervention trend
# b2 = discrete change after intervention
# b3 = sustained change to the slope after intervention
# Where:
# T = time count variable
# D = treatment dummy, 0 before , 1 after
# P = time since intervention count
Week 2 - Difference-in-Difference Models
Due Saturday, September 5th
Review:
Hypothesis testing with dummy variables: lecture notes
Varieties of the counterfactual: lecture notes
Reference:
Gertler, P. J., Martinez, S., Premand, P., Rawlings, L. B., & Vermeersch, C. M. (2016). Impact evaluation in practice. The World Bank. CH-07 Difference-in-Differences [link]
Wing, C., Simon, K., & Bello-Gomez, R. A. (2018). Designing difference in difference studies: best practices for public health policy research. Annual review of public health, 39. [pdf]
Week 3 - Panel Data with Fixed Effects
Due Saturday, September 12th
Reference:
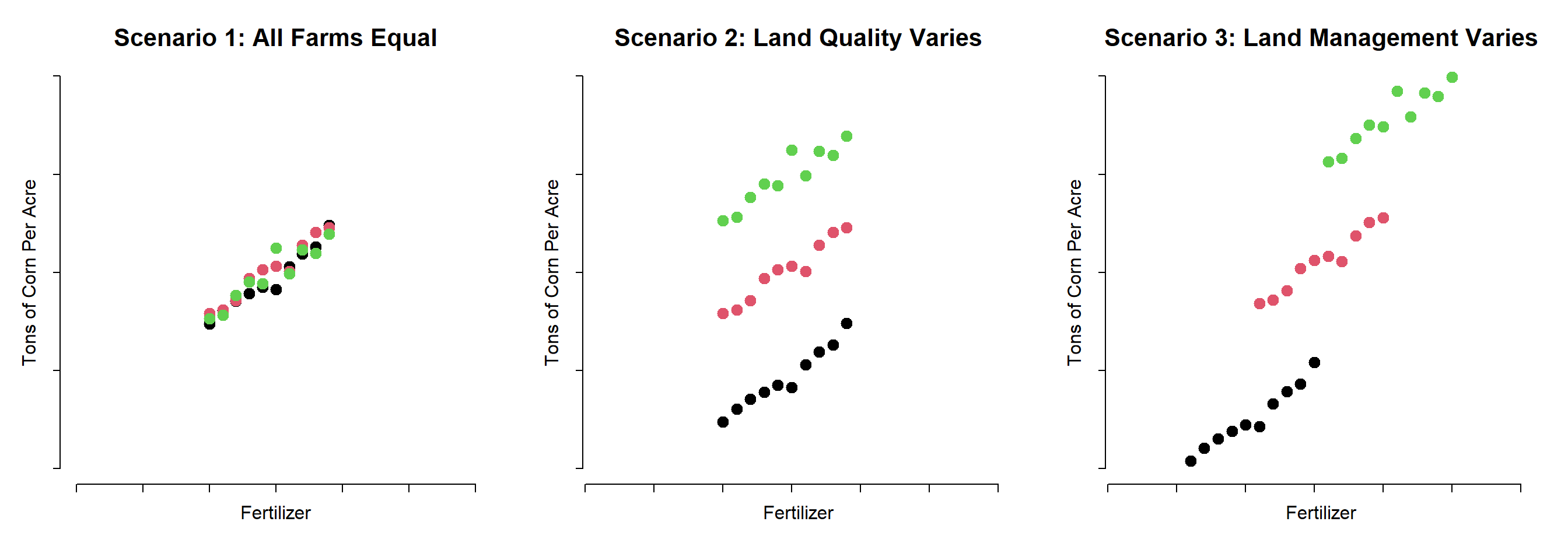
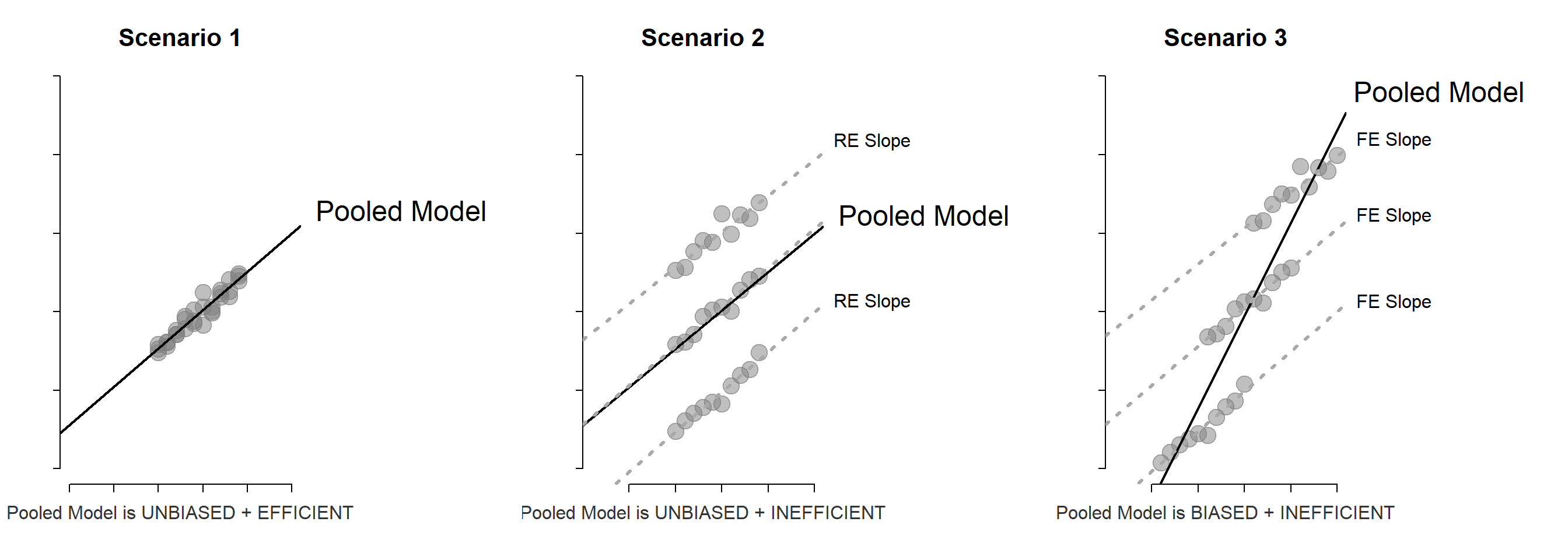
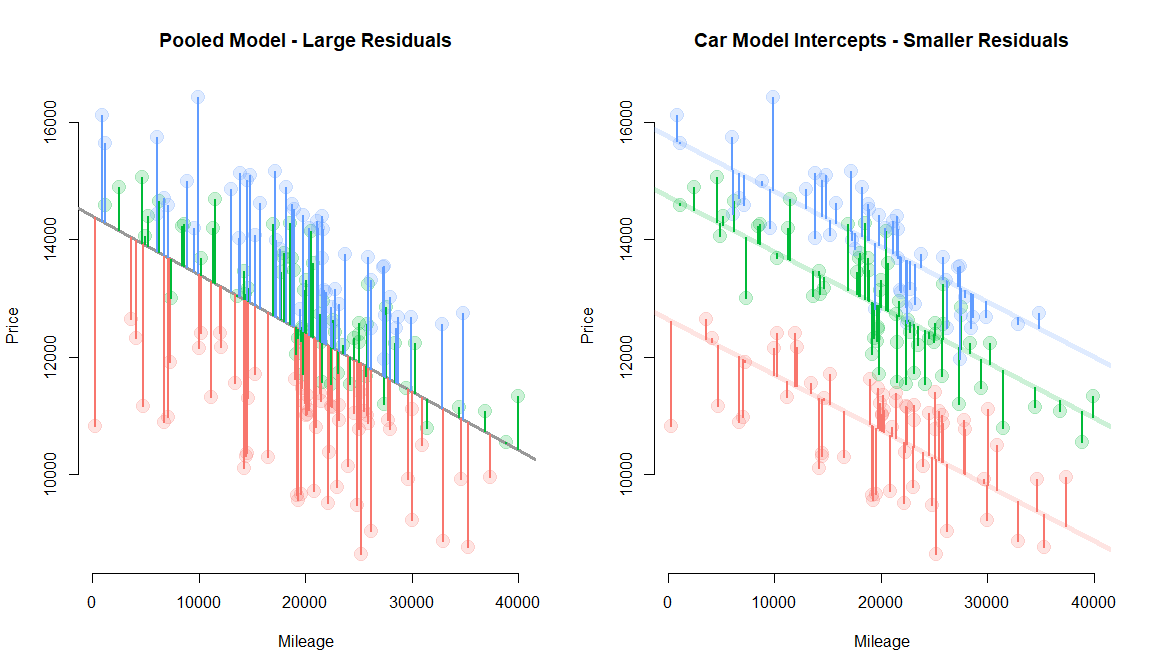
Panel models are necessary when group structure (farms A, B and C in this example) is correlated both with the level of treatment (amount of fertilizer used each season) and the outcome (some farms are more efficient).
If it is the land causing the productivity difference and land quality varies by farm, omitting the group ID (farm fixed effect) in the model would not bias the result. But it would make the model a lot less efficient (larger standard errors).
If the management practices of the farm are driving outcomes then better managers use fertilizer more intensely, but they also do a dozen other things not captured by the model that will improve productivity. In this case the farm ID is a proxy for management, and omitting it would result in bias.
So although group ID is measured differently than variables you have used before (it is a factor or a set of dummy variables) it operates similarly to other controls. If it is uncorrelated with the treatment then adding it will not change the policy slope, but it will make the model more efficient (explain more of the residual). If the group ID is correlated with the treatment then adding it to the model will fix bias.
This example explores the relationship between mileage and used-car price. Car models (e.g. lexus, ford, and honda) are correlated with price (a lexus is more expensive on average), but they are uncorrelatd with mileage (lexus owners and honda owners are driving similar amounts each year). Car values are very different when new, but each 10,000 miles driven reduces the value by the same amount.
# pooled model - all cars share same intercept
price = b0 + b1 × mileage + e
# random effects model
price[j] = a[j] + b1 × mileage + e
Where the data would be structured as follows:
# intercept in pooled model:
# all cars share one intercept
lexus | y 1 x |
b0 = ford | y 1 x |
honda | y 1 x |
# intercept in grouped model:
# each j (car company) has its own
lexus | y 1 0 0 x |
a[j] = ford | y 0 1 0 x |
honda | y 0 0 1 x |
Group-level variable is correlated with the outcome, but uncorrelated with the policy variable. Thus omission does not cause bias, but inclusion increases efficiency allowing the model to use a separate intercept for each group and thus moving regression lines closer to the data, reducing the model error.
Note that this is an over-simplified presentation of the topic. The terms fixed and random effects are used differently depending on discipline (see Gelman’s insightful discussion) and the model are estimated using different technique (see Stoudt blog, 2017).
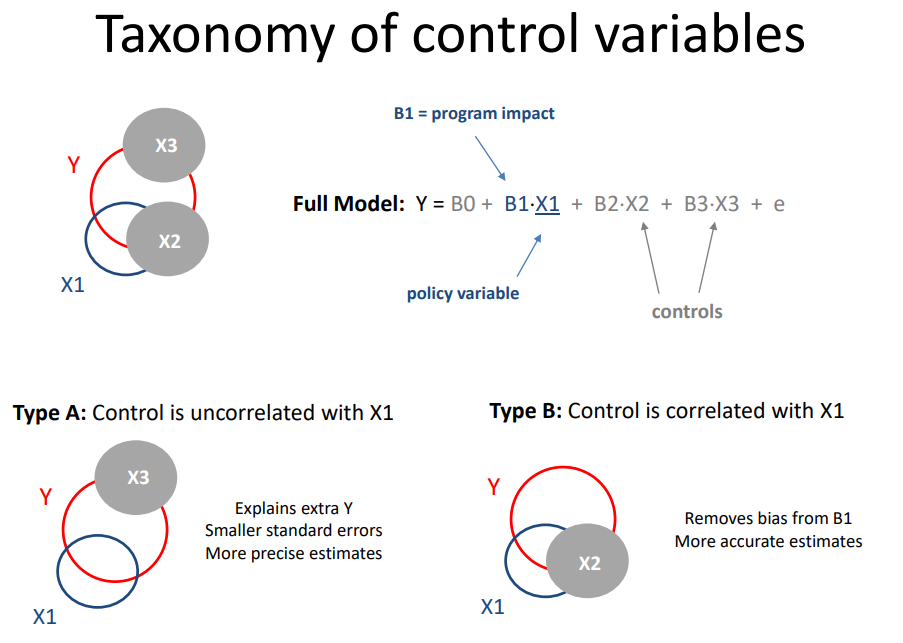
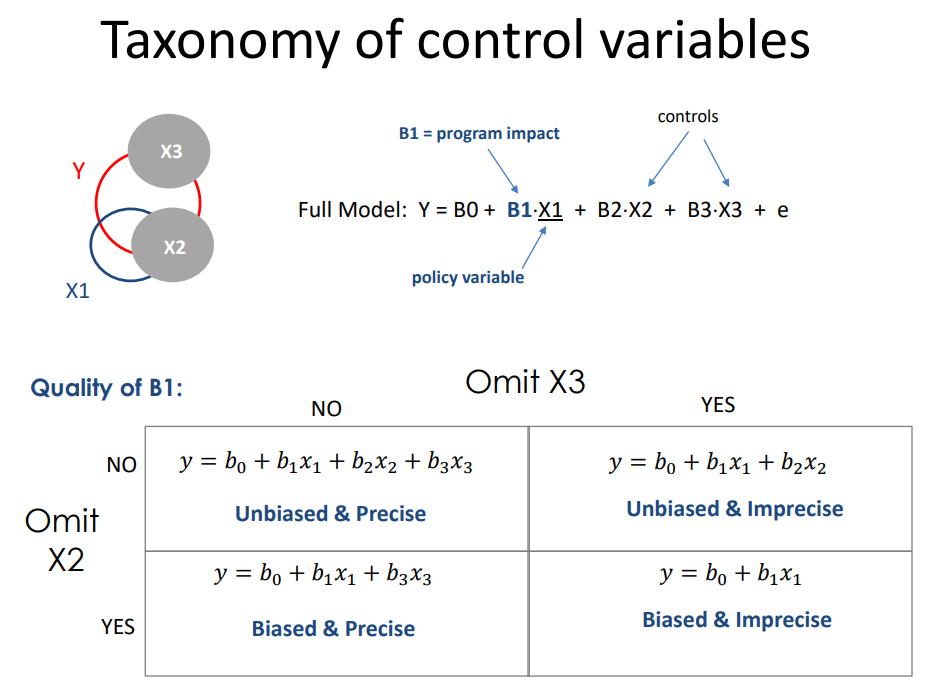
Recall the taxonomy of control variables.
- Random effects are like Type A controls
- Fixed effects are like Type B controls
Week 4 - Instrumental Variables
Due Saturday, September 19th
Example:
library( stargazer )
URL <- "https://ds4ps.org/cpp-525-spr-2020/lectures/data/iv-reg-example.csv"
dat <- read.csv( URL )
# Full Model - Correct Slopes
full.model <- lm( y ~ x1 + x2 + x3, data=dat )
# Naive Model (biased slopes)
naive.model <- lm( y ~ x1 + x2, data=dat )
# Instrumental Variable Correction to Naive Model
first.stage <- lm( x1 ~ z + x2, data=dat )
x1_hat <- fitted( first.stage )
second.stage <- lm( y ~ x1_hat + x2, data=dat )
stargazer( full.model, naive.model, second.stage,
column.labels = c("Full Model","Naive Model","IV Model"),
type="text",
omit.stat = c("rsq","ser","f","adj.rsq"),
digits=2 )
===================================================
Dependent variable:
--------------------------------------
y
Full Model Naive Model IV Model
(1) (2) (3)
---------------------------------------------------
x1 -2.00*** -3.54***
(0.0001) (0.03)
x1_hat -1.89***
(0.24)
x2 23.00*** 23.17*** 24.31***
(0.0003) (0.22) (0.91)
x3 14.00***
(0.001)
Constant -21.05 150,496.50*** 453,849.70***
(19.11) (12,387.91) (63,763.40)
---------------------------------------------------
Observations 1,000 1,000 1,000
===================================================
Note: *p<0.1; **p<0.05; ***p<0.01
Week 5 - Regression Discontinuity Design
Due Saturday, September 26th

Week 6 - Logistic Regression
Due Saturday, October 3rd
Example:
# DATA
URL <- "https://raw.githubusercontent.com/DS4PS/pe4ps-textbook/master/data/admissions.csv"
dat <- read.csv( URL, stringsAsFactors=F )
head( dat )
# Admission LSAT Essay GPA
# 1 1 160 55 2.78
# 2 1 173 79 0.33
# 3 0 149 38 1.86
# 4 1 173 34 3.74
# 5 0 130 52 2.99
# 6 1 160 59 1.06
#### LINEAR PROBABILITY MODEL
m1 <- lm( Admission ~ LSAT + Essay + GPA, data=dat )
summary( m1 )
# Marginal effects comparison:
#
# The standard deviation is a "reasonable"
# approximation of a big improvement.
#
# Which of these three things should I spend
# time on to improve my likelihood of admissions?
sd.lsat <- sd( dat$LSAT )
sd.essay <- sd( dat$Essay )
sd.gpa <- sd( dat$GPA )
b0 <- m1$coefficients[1]
b1 <- m1$coefficients[2]
b2 <- m1$coefficients[3]
b3 <- m1$coefficients[4]
sd.lsat * b1 # gains from improvement in LSAT
sd.essay * b2 # gains from improvement in essay
sd.gpa * sd.gpa # gains from improvement in gpa
# predicted prob of success (admissions) for a specific individual:
gpa <- 3.0
lsat <- 145
essay <- 90
b0 + b1*lsat + b2*essay + b3*gpa
#### LOGIT MODEL
m2 <- glm( Admission ~ LSAT + Essay + GPA, data = dat, family = "binomial" )
summary( m2 )
# logit link function: p is prob of success
p <- 1 / ( 1 + exp( - ( b0 + b1*x1 + b2*x2 ) ) )
# predicted prob of success (admissions) for a specific individual:
b0 <- m2$coefficients[1]
b1 <- m2$coefficients[2]
b2 <- m2$coefficients[3]
b3 <- m2$coefficients[4]
gpa <- 3.0
lsat <- 145
essay <- 90
# model reports log-odds
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
# convert log-odds to probabilities
1 / ( 1 + exp( - ( y.hat ) ) )
# marginal effects comparison:
# We must "center" other variables
# to look at marginal effects of one (LSAT here):
gpa <- mean( dat$GPA )
essay <- mean( dat$Essay )
lsat <- 150
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
1 / ( 1 + exp( - ( y.hat ) ) )
# Expected gains change greatly depending
# on the baseline, eg LSAT of 130 vs 150 vs 170
# value of 10-point increase in LSAT
# when current score is a 140
gpa <- mean( dat$GPA )
essay <- mean( dat$Essay )
lsat <- 140
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
p.140 <- 1 / ( 1 + exp( - ( y.hat ) ) )
lsat <- 150
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
p.150 <- 1 / ( 1 + exp( - ( y.hat ) ) )
p.150 - p.140
# value of 10-point increase in LSAT
# when current score is a 120
lsat <- 120
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
p.120 <- 1 / ( 1 + exp( - ( y.hat ) ) )
lsat <- 130
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
p.130 <- 1 / ( 1 + exp( - ( y.hat ) ) )
p.130 - p.120
# value of 10-point increase in LSAT
# when current score is a 170
lsat <- 170
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
p.170 <- 1 / ( 1 + exp( - ( y.hat ) ) )
lsat <- 180
y.hat <- b0 + b1*lsat + b2*essay + b3*gpa
p.180 <- 1 / ( 1 + exp( - ( y.hat ) ) )
p.180 - p.170
Week 7 - Propensity Score Matching
Due Saturday, October 3rd